DFlash and DDTree: 8x Faster LLM Inference via Block Diffusion and Draft Trees
Two papers dropped in the last two months that compound. DFlash (Z Lab, February 2026) replaces the autoregressive drafter in speculative decoding with a block-diffusion model. DDTree (Technion, April 2026) reuses DFlash's per-position distributions as a verified draft tree. Together they hit 8.22x lossless speedup on Qwen3-Coder-30B-A3B-Instruct for HumanEval, eclipsing EAGLE-3. DFlash has first-class support in vLLM and SGLang; DDTree ships a standalone reference implementation and community ports are in progress.
This post walks through what each method actually does, why the combination is more than the sum of its parts, the benchmarks, and how to try it on your own hardware.
What is DFlash?
DFlash (Block Diffusion for Flash Speculative Decoding) is a 2026 method that replaces the autoregressive drafter in speculative LLM decoding with a block-diffusion model. Instead of producing one draft token per forward pass, DFlash emits a full block of k tokens in a single pass by denoising a masked sequence conditioned on the target model's hidden states. The target model still verifies every token, so DFlash is lossless -- you get up to 8.22x throughput on Qwen3-Coder-30B with no quality degradation. DFlash has first-class support in vLLM and SGLang for LLM inference.
What is DDTree?
DDTree (Diffusion Draft Tree) reuses DFlash's per-position distributions as a verified draft tree instead of a single trajectory. By branching on the top-k candidates at each position, DDTree gives the target many parallel hypotheses to verify in one forward pass, raising acceptance length without extra drafter compute. DFlash + DDTree together is what eclipses EAGLE-3 on Qwen3-Coder-30B HumanEval.
The bottleneck that speculative decoding targets
Autoregressive decoding produces one token per forward pass. On modern hardware that one pass is dominated by memory bandwidth — you load the entire model's weights from HBM just to emit a single token. The arithmetic units sit mostly idle. For a 30B model at bf16 that's ~60GB of weights moved for each token.
Speculative decoding reclaims that idle compute. A small "drafter" proposes k candidate tokens cheaply, then the large "target" model verifies all k in a single forward pass. If all k are accepted you get k tokens for the cost of one target call. If they diverge, you fall back and keep the verified prefix. The canonical framing is in Leviathan et al. 2022; EAGLE-3 (Li et al. 2025) has been the strongest drafter for the last year.
The drafter problem: every classical drafter — including EAGLE — is itself autoregressive. Drafting k tokens costs k forward passes through the drafter. The drafter is cheap but still serial. DFlash attacks exactly this.
DFlash: one forward pass for the whole draft block
DFlash (Block Diffusion for Flash Speculative Decoding) replaces the drafter with a block-diffusion model. Instead of emitting one token at a time, the drafter emits an entire block of k tokens in a single forward pass by denoising a masked sequence conditioned on the target model's context features.
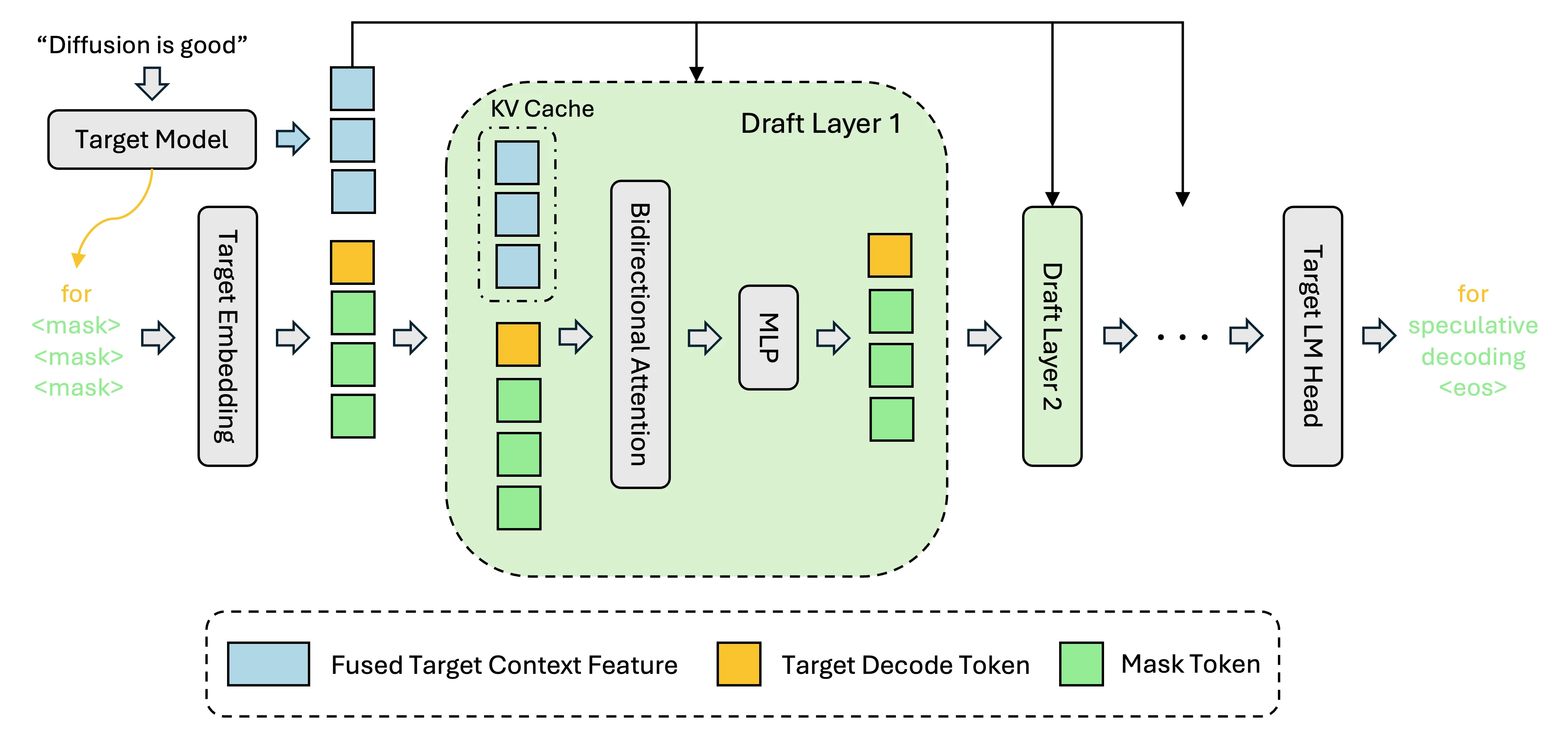
The quality trick is that the drafter isn't standalone — it reads hidden states from the target model (the same trick EAGLE uses) so it stays aligned with what the target would produce. Without that conditioning, a block diffuser would drift.
The authors report >6x lossless acceleration across standard benchmarks and up to 2.5x higher speedup than EAGLE-3 depending on workload. "Lossless" here means the accepted token distribution matches the target model exactly — same output guarantees as classical rejection-sampling speculative decoding.
Three things make this work:
- Parallel draft emission. One forward pass produces the full block; GPU utilization jumps because the drafter now does useful batch-2 work instead of sequential batch-1 work.
- Per-position distributions come free. Unlike an autoregressive drafter (which samples one token, then conditions on it), a diffusion drafter emits a distribution for every position in the block simultaneously. DDTree exploits this.
- Target-model conditioning. The drafter fuses on intermediate hidden states from the target, keeping acceptance rate competitive with EAGLE despite emitting the whole block in parallel.
Code and weights: github.com/z-lab/dflash. Project page: z-lab.ai/projects/dflash.
DDTree: verify a tree, not a trajectory
Two months after DFlash shipped, Liran Ringel and Yaniv Romano (Technion) asked an obvious-in-hindsight question: vanilla DFlash verifies one trajectory per round, but the drafter produced distributions for every position. The non-mode probability mass is thrown away.
From the abstract: "Vanilla DFlash ... still verifies only a single drafted trajectory per round, potentially limiting its acceptance length." (arXiv:2604.12989)
DDTree builds a draft tree from those distributions. Each position in the block contributes multiple candidate tokens (not just the argmax); the tree branches through the plausible trajectories. A tree of size B is then verified in a single target-model forward pass using an ancestor-only attention mask — each drafted node attends, within the tree, only to root, ancestors, and itself, plus the past KV cache.
Node selection is a best-first search with a max-heap, where the surrogate priority is defined by the drafter's own output probabilities. The paper bounds the bookkeeping: "at most B pops and at most 2B pushes, and the heap size is O(B) throughout."
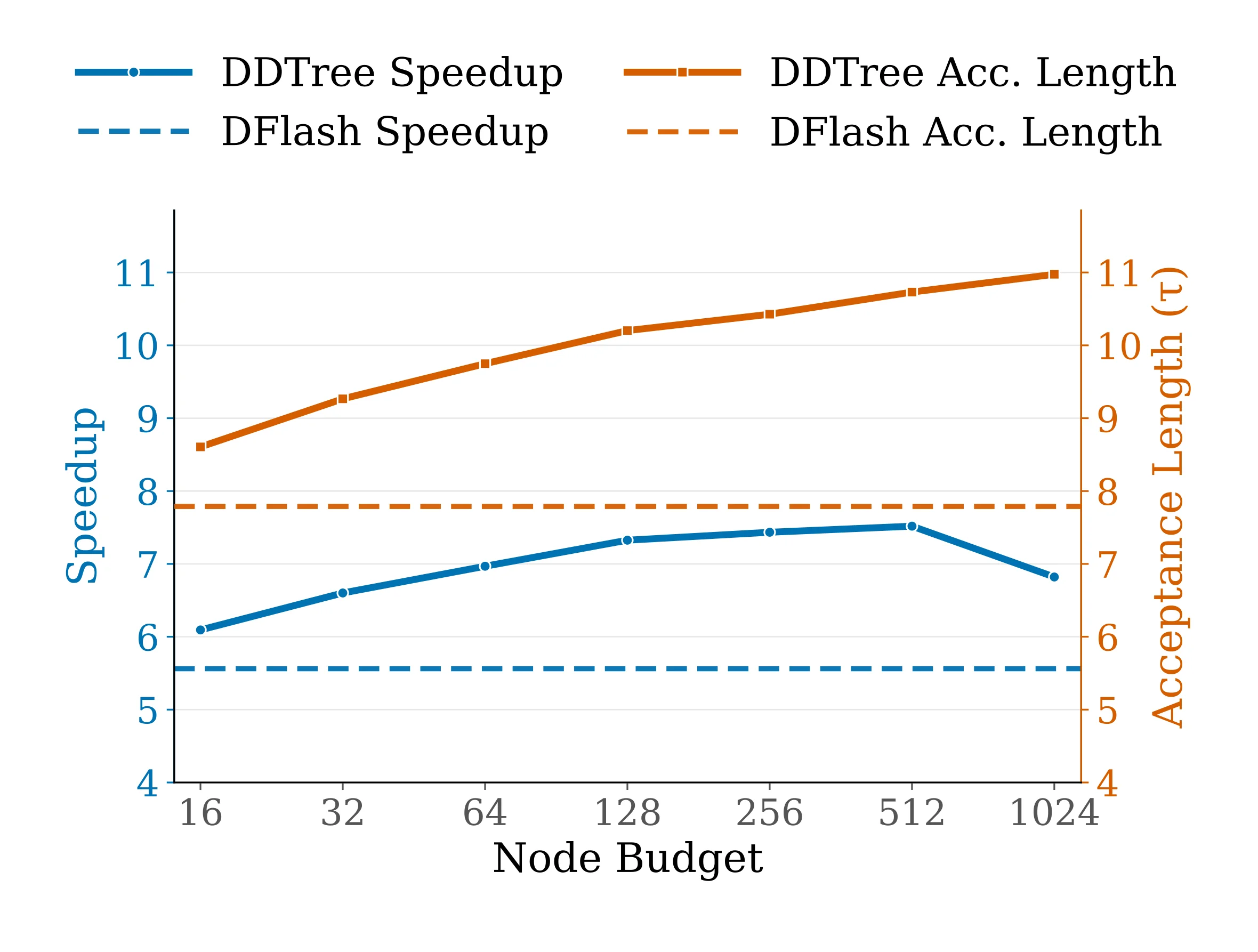
The tree budget B is a knob. The authors sweep {16, 32, 64, 128, 256, 512, 1024} and find the sweet spot at 256–512 on current GPUs. Below that you underuse the verification pass; above it the target forward pass starts to slow down under mask complexity.
Why this layers so cleanly: an autoregressive drafter would have to recompute for each branch — drafting two alternative continuations means two forward passes. A diffusion drafter already produced the distributions in a single pass. DDTree just builds a tree out of information that was already there. The verification-side tree is essentially free.
DDTree is lossless — it preserves the target model's output distribution exactly via the standard speculative-decoding acceptance rule applied recursively across the tree.
Code: github.com/liranringel/ddtree (MIT). The repo ships both dflash.py and ddtree.py side by side, so you get the drafter and the tree extractor in one install. Project page: liranringel.github.io/ddtree.
Benchmarks on Qwen3
The DDTree paper reports on three Qwen3 models at T=0 (greedy). DDTree wins on every reported dataset-model-temperature combination (60/60). A few representative rows:
| Benchmark | Model | Vanilla DFlash | DDTree | Gain |
|---|---|---|---|---|
| MATH-500 | Qwen3-8B | 5.56x | 7.52x | +35% |
| HumanEval | Qwen3-8B | 4.84x | 6.90x | +43% |
| HumanEval | Qwen3-Coder-30B-A3B | 6.09x | 8.22x | +35% |
| GSM8K | Qwen3-8B | 4.78x | 6.75x | +41% |
Speedups are relative to vanilla autoregressive decoding. The DFlash column is already strong; DDTree adds 35–43% on top. Reasoning-heavy workloads (MATH, GSM8K) benefit more than short-answer tasks because longer generations give the tree more room to pay off.
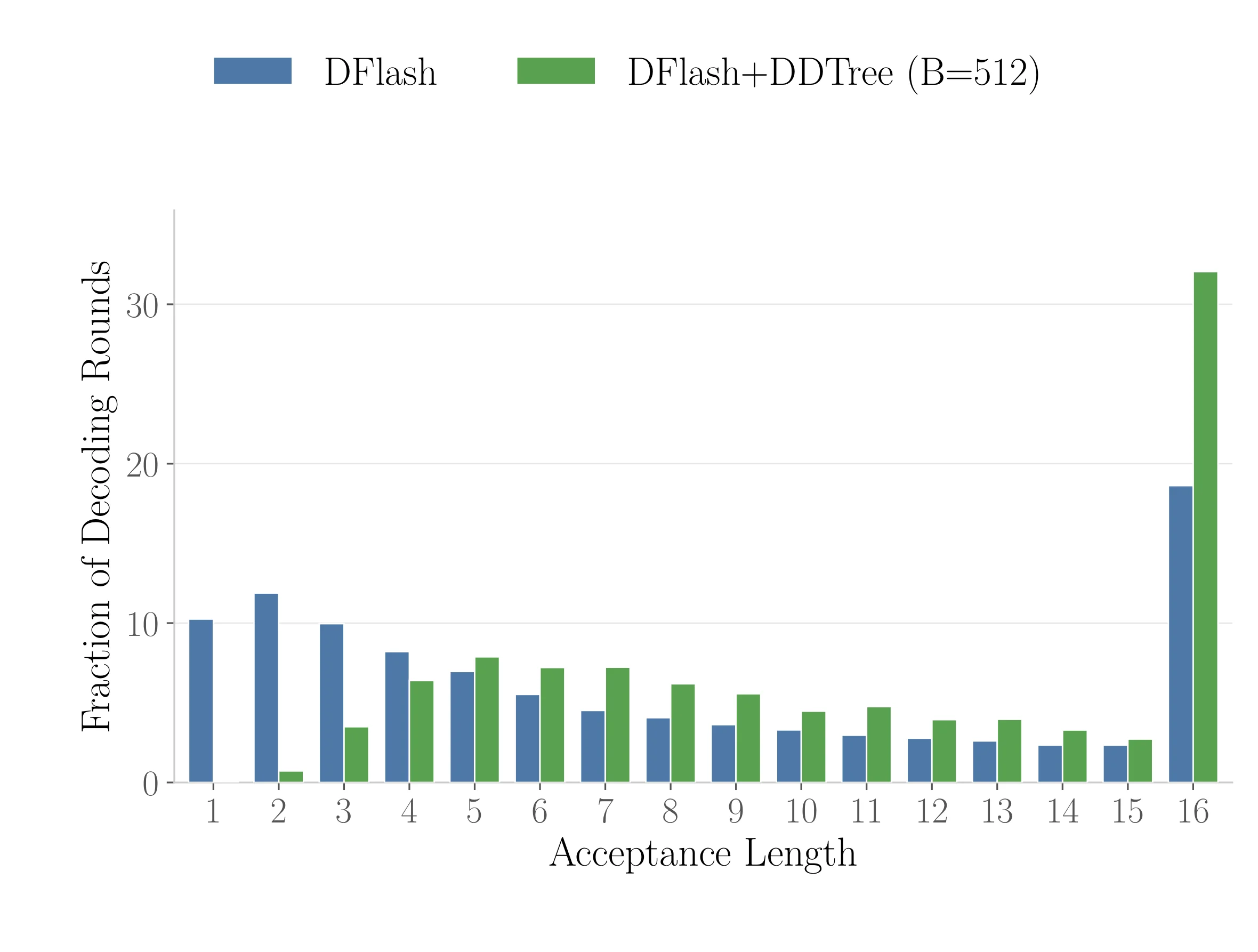
Caveat I want to flag: the EAGLE-3 head-to-head numbers are not in the DDTree paper. The comparison to EAGLE-3 is inherited transitively from the DFlash paper. If you're picking a drafter for production, run the comparison yourself on your workload.
vLLM integration and the GB10 result
The reason I wrote this post today is that a usable integration landed fast. Mitko Vasilev (@iotcoi) ported DDTree into a vLLM fork within days of the paper and benchmarked it on an NVIDIA DGX Spark (GB10) running Qwen3.5 on CUDA 13.1, reporting sustained throughput north of 80 tok/s per the NVIDIA DGX Spark / GB10 forum thread. That is fork-not-upstream as of writing — worth tracking as the PR makes its way into the main vLLM repo.
A community MLX port exists for Apple Silicon experimentation, though the Metal kernels for the ancestor-only attention mask lag the CUDA path — expect lower absolute speedups than the paper's numbers until that catches up.
How to try it
DFlash on vLLM (verbatim from the z-lab/dflash README — requires the vLLM nightly):
uv pip install -e ".[vllm]"
uv pip install -U vllm --torch-backend=auto --extra-index-url https://wheels.vllm.ai/nightly
vllm serve Qwen/Qwen3.5-27B \
--speculative-config '{"method": "dflash", "model": "z-lab/Qwen3.5-27B-DFlash", "num_speculative_tokens": 15}' \
--attention-backend flash_attn \
--max-num-batched-tokens 32768On SGLang:
python -m sglang.launch_server \
--model-path Qwen/Qwen3.5-35B-A3B \
--speculative-algorithm DFLASH \
--speculative-draft-model-path z-lab/Qwen3.5-35B-A3B-DFlash \
--speculative-num-draft-tokens 16 \
--attention-backend trtllm_mhaFor DDTree specifically, the reference implementation lives in liranringel/ddtree — a research codebase, not a production server. Reproduce the paper's Table 1:
git clone https://github.com/liranringel/ddtree
cd ddtree
pip install -r requirements.txt
bash run_benchmark.shThe repo ships dflash.py and ddtree.py side by side, so you can toggle between vanilla DFlash and DDTree on the same drafter weights. A community MLX port (humanrouter/ddtree-mlx) exists for Apple Silicon experimentation.
Drafter weights are per-target-model. Z Lab publishes drafters across the Qwen3.5 family (4B / 9B / 27B / 35B-A3B), Qwen3-Coder-30B-A3B, Kimi-K2.5, gpt-oss (20B / 120B), and Llama-3.1-8B-Instruct — the full list lives in the z-lab Hugging Face collection. For unlisted targets the recipe needs open-sourcing; the DFlash repo says it's on the way.
What this doesn't fix
Speculative decoding is a latency trick for single-stream or low-batch serving. Under high batch sizes the target model's compute is already saturated — drafting doesn't buy you much because there's no idle memory bandwidth left to reclaim. The paper focuses on batch-1 and low-batch regimes; high-throughput inference remains a different optimization problem.
Also: the drafter still needs to be trained well against your target. A mismatched drafter tanks acceptance rate. You can't drop a Qwen3-8B drafter in front of Llama-3.1-70B and expect 6x.
And tree budgets don't scale linearly. Going from B=256 to B=1024 gave the paper roughly 10% more speedup, not 4x. The distribution-mass concentration at each position runs out fast — most of the tail isn't worth verifying.
The broader pattern
What makes DFlash + DDTree satisfying as a two-paper pair is that each exploits a structural asymmetry the field had been ignoring:
- DFlash: the drafter was always the sequential bottleneck inside speculative decoding — the thing that was supposed to be cheap became the bottleneck at long draft lengths. Block diffusion makes it genuinely parallel.
- DDTree: a diffusion drafter produces a distribution per position "for free" — the information was there; classical speculative decoding just threw it away.
The second paper is the kind that only becomes obvious once the first exists. Which is probably why it shipped two months later, from a completely different lab, and both were integrated into the same serving stacks within weeks. Worth watching what else falls out of the diffusion-drafter design now that the downstream exploits are in the open.
References
- Chen, Liang, Liu. DFlash: Block Diffusion for Flash Speculative Decoding. arXiv:2602.06036, February 2026. Code: z-lab/dflash.
- Ringel, Romano. Accelerating Speculative Decoding with Block Diffusion Draft Trees. arXiv:2604.12989, April 2026. Code: liranringel/ddtree. Project: liranringel.github.io/ddtree.
- Leviathan, Kalman, Matias. Fast Inference from Transformers via Speculative Decoding. ICML 2023 — the canonical speculative-decoding framing.
- Li et al. EAGLE-3: Scaling up Inference Acceleration of Large Language Models via Training-Time Test. 2025 — previous state-of-the-art drafter.
- NVIDIA developer forum thread: DDTree plus Diffusion Drafting (DFlash) to Optimize GB10.
- vLLM: vllm-project/vllm. SGLang: sgl-project/sglang.